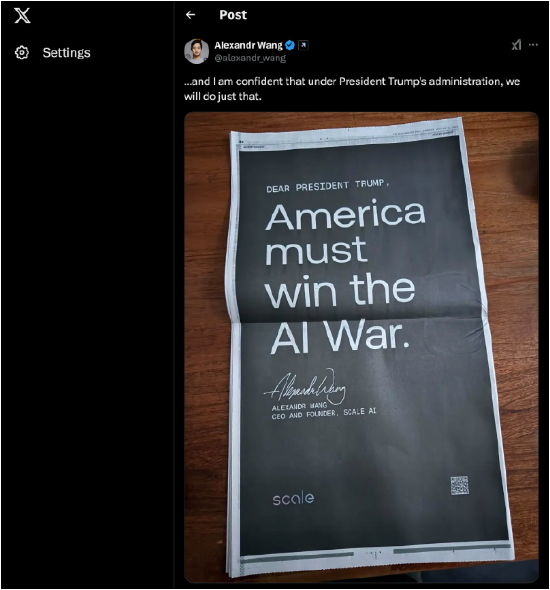
�����҂������˶����^ʥ�Q�ĕr��һ���Ї�����҅s�l�����������AIģ�͡��@�@Ȼ�����������x���L���ԁ�����������AI������̎��ȫ���I�ȵ�λ����DeepSeek������ģ�ͅs�ڸ�׃�@һ��֡��� Scale AI�Ą�ʼ�˼�CEO���vɽ������Alexandr Wang���ڽ�������ý�w���L�r�@�Ӹп���
�̶̰낀�r�g��һ���Ї�����Ұl����AIģ�;��������y�����ŵČ��������������������AI�I�ĿƼ����^��AI���F�ٵ����g���ң��������˶����ܵ��ˁ����Ї�AI�ИI�ď��қ_�������������@���ǣ��Ї�AI�ИI�����ܳ��ڹ��ƺ������T����r�£����F�ˏ�����܇��
�M�ճ����ս����
�@������Ҿ��ǁ����Ї���DeepSeek��2023�ꄂ��������������ȥ����װl����һ�����M�_Դ�Ĵ��Z��ģ�͡�����ԓ��˾�l����Փ�ģ�DeepSeek-R1�ڶ������W���������ʜyԇ�г�Խ���ИI�I�ȵ�OpenAI o1��ģ�ͣ��������ܡ��ɱ����_���Ե�ָ�˷��扺��������AI���^��
�Ƽ��ИI��Ҫ�Ô����fԒ����һϵ�е��������ʜyԇ�У�DeepSeek��ģ���ڏď��s���}��Q�����W�;��̵ȶ����I��Ĝʴ_���ϣ���Խ��Meta��Llama 3.1��OpenAI��GPT-4o�Լ�Anthropic��Claude Sonnet 3.5��
�������ܣ�DeepSeek�ְl��������ģ��R1��ͬ�����T��������yԇ�г�Խ��OpenAI���µ�o1����AIME 2024���W���ʜyԇ�У�DeepSeek R1ȡ����79.8%�ijɹ��ʣ����^��OpenAI��o1����ģ�͡��ژ˜ʻ����a�yԇ�У���չʾ�ˡ����Ҽ����ı��F����Codeforces�ϫ@����2��029��Elo�u�֣����^��96.3%����������֡�
Scale AI�tʹ���ˡ�������ԇ����Humanity��s Last Exam����yԇAI��ģ�ͣ������Á��Ԕ��W��������������W�����ṩ�ġ����y���}�����漰���µ��о��ɹ����ڜyԇ���������µ�AIģ�ͺ��vɽ�������ò�ٝ�@��DeepSeek������ģ�͡����H���DZ��F���ɫ�ģ����������co1����õ�����ģ�Ͳ������¡���
�����䏈���f��DeepSeek������AI�ИI���l��һ�����𣬸����l��ý�w�Ġ�������������е�����ý�w�ͿƼ�ý�w����������Ї�AIģ�ͳ��^�����@һ��ը�����̶̎���r�g��DeepSeek���ѽ��ɞ��O�������̵�������һ�����M���ã�����OpenAI��ChatGPT��
���ܳɱ����^
���Ĝyԇ���ȽY�������ò����������е�AI���^���LͶ�ͼ��g�ˆT��ֻ�ܳ��J���ڴ�ģ���@���I��DeepSeek�����ѽ����Ժ�OpenAIƽ��ƽ�����Ї��ѽ�����������
ܛ��ϯ���й��_�ف����{������Satya Nadella�������罛��Փ����Մ��DeepSeek�r��ʾ����DeepSeek����ģ������ӡ����̣��������H��Ч�ؘ�����һ���_Դģ�ͣ��܉�������Ӌ��r��Ч�\�У�������Ӌ��Ч�ʷ�����F��ɫ���҂���횷dz��dz��J��،����Ї���AI�M������
�Ї�AI���H������Խ�����ǽ������ݡ�����T��AI���^�е��ͺ����DeepSeek�ĵ����ɱ���R1ģ�͵IJ�ԃ�ɱ��H��ÿ���f��token 0.14��Ԫ����OpenAI�ijɱ���7.50��Ԫ��ʹ��ɱ�������98%��
�����С�Ӳ�����DeepSeek�H�H���˃ɂ��r�g�����M�˲���600�f��Ԫ�ʹ����˴��Z��ģ��R1�����������õ�߀�������^����Ӣ���_H800оƬ���@��ζ��ʲô���ȷ����Ї�AI��˾��Ȼ�_����ͨ�I܇���͌��F�ˏ�����܇���ڸ�ِ�г�Խ�˹�Ⱦ��^���ij�����܇��
����Ӗ���ɱ�������DeepSeek�ĈFM��Ҳ�c����T��AI���^������ͥ��DeepSeek��ʼ�����ķ��ڽM���о��Fꠕr����δ���ҽ���S�����Y��ܛ�����̎������nj�ע�ځ��Ա������A��피���У�IJ�ʿ�����S��������피��W�g�ڿ��l��Փ�ģ����ڇ��H�W�g���h�ϫ@������ȱ���ИI��
���҂��ĺ��ļ��g��λ��Ҫ�ɽ�����^ȥһ���ꮅ�I���ˆT���Σ������ķ���2023�����ý�w���L�r��ʾ���@�N��Ƹ���������ڠI��һ�����Ʌf���Ĺ�˾�Ļ����о��ˆT�������ó����Ӌ���YԴ���_չ����һ����о��Ŀ���@�c�Ї����y���W��˾�γ��r�����ȣ��ں����У��F�ͨ�����YԴ�������ҡ�
�]�жڷe피�GPU���]���Д��Y��AI�˲ţ��]�и߰����\�гɱ���һ�ӿ����ó���ѵĴ�ģ�ͣ�DeepSeek��һ�ж����AI���^���е��چʡ�
��Ⱦ��^����چ�
������ľ��^������ô����DeepSeek�أ�OpenAI��ʼ�˼�CEO�W������Sam Altman���ı�B�˸��X���c�ᡣ�����罻ý�w�ϱ�ʾ����������֪��Ч�ķ����������ף���̽��δ֪�I��t��M���𡣡� �@һ��Փ���V�����x�錦DeepSeek�İ��S����ʾ�Ї�AIģ��ȱ�������Ą��£��H�H���ڏ��ƬF�е���Ч������
Perplexity AI��CEO˹������˹��Arvind Srinivas��ӡ���ˣ����Ј�Ӱ푵ĽǶȁ������@һ�l������DeepSeek�ںܴ�̶��Ϗ�����OpenAI o1 mini���_Դ������������Ҳٝ�@��DeepSeek�Ŀ��ٲ������������������Ѹ�ٵ���Ʒ�����@���c��������ʾ���Լ��ĈFꠕ���DeepSeek R1��������������Perplexity Pro��
Stability AI�Ą�ʼ��Emad Mostaque��ʾDeepSeek�İl���o�Y�����ԣ�ĸ������֎����ˉ���������������һ���I����10�|��Ԫ��ǰ�،���ҬF�ڟo���l��������ģ�ͣ�������o������DeepSeek���
Meta AI��ϯ�ƌW�җ�������Yann
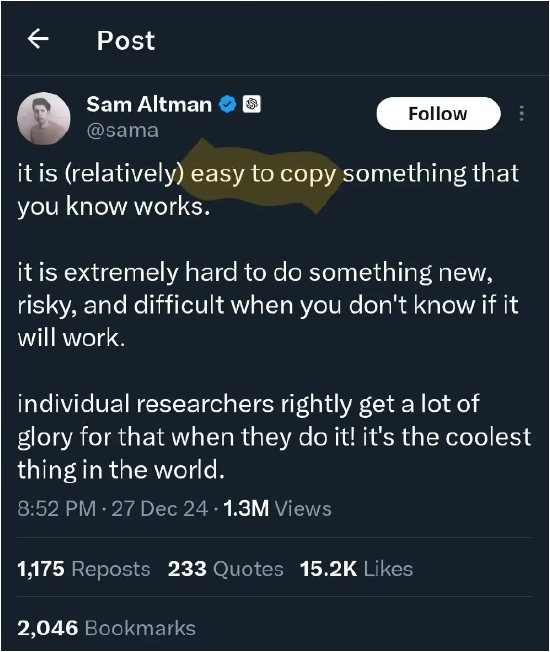
LeCun�������ˣ��t���{�Ї����������_Դ�ă���ȡ�óɹ������ڌ�DeepSeek�ijɹ���ʾٝ�p��ͬ�r���{��DeepSeek�ijɹ�������ζ���Ї���AI�I��Խ�����������C�����_Դģ�����ڳ�Խ�]Դϵ�y��
��������ʾ��DeepSeek���_Դ�о����_Դ���a������˜\��������������뷨���������˹����Ļ��A���M�Є��¡����������Ĺ����ǹ��_���_Դ�ģ������˶����Ы@�档�@�w�F���_Դ�о����_Դ���a�������� ���J�飬DeepSeek�ijɹ���F�_Դ���Bϵ�y���Ƅ�AI���g�M���е���Ҫ�ԣ�����ͨ�^�����ͅf�����_Դģ���܉F���ل��ºͰlչ��
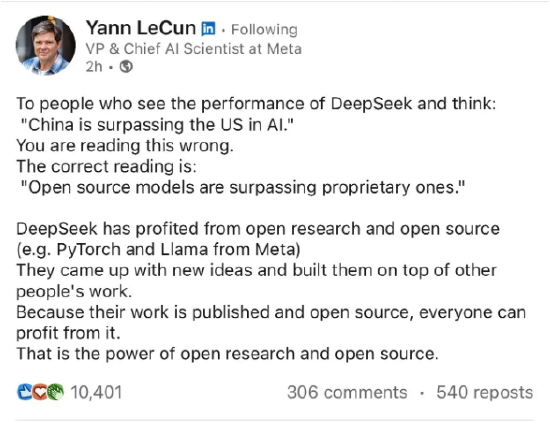
��Meta�Ȳ��ɛ]���@ô�������^ȥ���죬������ƽ�_teamblind����һ������Meta�T�����N�ӱ����������ӷQMeta�Ȳ����DeepSeek��ģ�ͣ��F���ѽ��M��ֻ�ģʽ�����H�����DeepSeek�ă�����F���������O�͵ijɱ��͈FM�ɡ�
��һ�ж����DeepSeek-V3�ij��������ڻ��ʜyԇ���ѽ�Llama 4����Ҋ�I�������y�����ǣ�һ���Ї���˾�H��550�f��ԪӖ���A����������@һ�c���F��Meta�Ĺ��̎������ڠ��֊Z��ط���DeepSeek��ԇ�D�������е�һ�п��ܼ��g���@�^�ǿ䏈�����ң����������GenAI�аl���T�ľ��~Ͷ����l������T��һ���߹ܵ�н�Y�ͳ��^Ӗ������DeepSeek V3�ijɱ��������@�ӵĸ߹�߀�Д�ʮλ������ԓ�����ߌӽ�����
��Ч�㷨������܇
��ô��DeepSeek���������ӌ��F������܇�����������@��ɱ�ֻ�����^����r�£��������������������Խ���AI���^�Ĵ�ģ���أ�
�����ij��ڹ��Ƈ����������Ї��Ƽ���˾�ԡ�����ʽ���ķ������c�˹����ܸ�������ͨ�^�o�ޔUչоƬ��ُ�����LӖ���r�g����ˣ�������Ї���˾�����c�������Α��ã�������������ģ�͡���DeepSeek�����°l���C�����@�ٵ���һ�l��·�ǣ�ͨ�^����AIģ�͵Ļ��A�Y����������Ч�����������YԴ��
��������YԴ���㣬DeepSeek���ò��_�l����Ч��Ӗ��������������ͨ�^һϵ�й��̼��g������ģ�ͼܘ������������ƻ�оƬ�gͨ�ŷ������p���ֶδ�С�Թ�ʡ�ȴ棬�Լ������Ե�ʹ�Ì��һ��ģ�ͣ�Mixture-of-Experts����������Mercator�о�����ܛ�����̎��صϡ�����Wendy Chang����ʾ�����S���@Щ�����������r�����ɹ��،��������������a���ģ�����ஔ�˲���ijɾ͡���
DeepSeek߀�ڡ����^����ע��������Multi-head Latent Attention��MLA���͡����һ��ģ�͡�����ȡ�����ش��Mչ���@Щ���g�OӋʹDeepSeek��ģ���߳ɱ�Ч�棬Ӗ�������Ӌ���YԴ�h���ڸ������֡����ϣ����о��C��Epoch AI�Q��DeepSeek������ģ�̓Hʹ����Meta Llama 3.1ģ��ʮ��֮һ��Ӌ���YԴ��
�Ї�AI�о��ˆT���F���S�����J���b���ɼ��ijɾͣ�һ�����M���_Դ��AIģ�ͣ������ܿ�������������ԽOpenAI�����M������ϵ�y�������˲�Ŀ���������Č��F��ʽ��AIͨ�^ԇ�e���ҌW�����������ČW����ʽ��
�о�Փ���Ќ�������DeepSeek-R1-Zero��һ��ͨ�^��Ҏģ�����W����RL��Ӗ����ģ�ͣ��o��O���{��SFT������������E��չʾ��Խ��������������
�������W������һ�N������ģ�����������_�Q�ߕr�@�ê�������e�`�Q�ߕr�ܵ����P�����o��֪���Ă����Ă������^һϵ�ЛQ�ߺ������W����ѭ���@Щ�Y��������·����
DeepSeek R1��AI�lչ��һ���D���c����������Ӗ���еą��c���١��c�����ڴ����O��������Ӗ����ģ�Ͳ�ͬ��DeepSeek R1��Ҫͨ�^�Cе�����W���M�ЌW���������|����ͨ�^���ͫ@�÷�������Q���}��ԓģ�������ڛ]�����_���̵���r�£��lչ����������C�ͷ�˼�ȏ��s������
�S��ģ�ͽ��vӖ���^�̣�����Ȼ�W���˞���s���}�������ġ�˼���r�g�������lչ���������e�`���������о��ˆT���{��һ�����D��r�̡���ģ�͌W���������u��������Ć��}��Q���������@�����]�б����_����ȥ�������顣
�_Դģ�͏V�@ٝ�p
ֵ��һ����ǣ�DeepSeekԸ�⌢�䄓�³ɹ��_Դ��ʹ����ȫ��AI�о���^�Ы@���˸����ٝ�p�� �c����ģ�Ͳ�ͬ��DeepSeek R1�Ĵ��a��Ӗ��������MIT�S���C����ȫ�_Դ���@��ζ���κ��˶����ԫ@ȡ��ʹ�ú���ԓģ�ͣ��]���κ����ơ�
���S���Ї�AI��˾���f���_�l�_Դģ�����s�������������ֵ�Ψһ��ʽ������@�ӿ������������Ñ���ؕ�I�ߣ�����ģ�Ͳ�����L����OpenAI��u���]���Į��£�DeepSeek���_Դ�õ���AI�ĘI�ˆT�Ľ��ڷQٝ��
Ӣ���_�Y���о��T���\��Jim Fan����ʿٝ�P��DeepSeekǰ��δ�е����ȣ���ֱ�ӌ����cOpenAI��ԭʼʹ�����ᲢՓ�����҂�������һ����������˾����OpenAIԭʼʹ���ĕr�g���ϡ��������_�ŵġ�ǰ�ص��о����x�������ˣ������\ָ����
���\ָ����DeepSeek�����W����������Ҫ�ԣ������������ǵ�һ��չʾ[�����W��]�w݆���m���L���_Դܛ���Ŀ������߀ٝ�P��DeepSeekֱ�ӷ�����ԭʼ�㷨��matplotlib�W�����������������ИI�и���Ҋ�ij����ӹ��档
��ѭͬ�ӵ������������и����C��Փ�C���Ƽ���I��Arnaud Bertrand����f���������_Դģ�͵ij��F���܌�OpenAI�_��������@��ʹOpenAIģ�͌����M��Ը���ҵĸ��Ñ������������ͣ��Ķ��p��OpenAI���̘Iģʽ�����@�����Ͼ������˰l����һ���ciPhone�ஔ���֙C�����ۃr��30��Ԫ������1000��Ԫ���@�Ǒ��Եġ���
���ڹ������R����
�@��Ӣ���_���f��DeepSeek�ęM�ճ�����һ���������ء��ܶ�AI�ИI��ʿ�����_ʼ˼����һ�����}����ȻDeepSeek����һ��оƬ��鎸��Ϳ���Ӗ������ŵĴ�ģ�ͣ���ô�Ƽ����^��߀��Ҫ�^�m������X��ُӢ���_������GPU��@�����}��˼�O�֡�
������֪���������������AIоƬ���\���Ї��o����ُӢ���_������ܵ�AIоƬ����H800�t�Ǹ�����A100оƬ��鎸�档�cA100��ȣ�H800�ĺ��Ĕ������l�ʺ��@�淽�����@�^�ͣ������Ͻ�����s��10-30%֮�g����Ҫ����Ҫ피������Ĉ����������е�Ҏģ��AIӖ���c�����΄ա�H800�ăȴ控���������� 1.5 TB/s����A100 80GB�汾���_�� 2 TB/s���@��ֱ��Ӱ푔���̎����������������ȌW���΄��С�
Scale AI�ā��vɽ�����Գ��J�飬DeepSeek��оƬ���������h�h����������������_��ʾ���Լ��J��DeepSeek���ٓ���5�f�KH100�����������������w���֡�
H100��������A100�������߱����@��3�f��Ԫ���۵�피�GPUҲ��Ŀǰ��ȿƼ����^�����ȓ�ُ��܊��Meta��ܛ�����^��ُ��15�f�KH100���ȸ衢���ĺ́��R�d����ُ��5�f�K���R˹�˵�xAI��������10�f�KH100�M�ɵij���Ӌ��C��Ⱥ����Ӗ�����A��ģ��Grok3��
���vɽ�����Mһ����ʾ��δ���Ї�AI�ИI���ܕ����R�������𣬡�δ���������ܵ��҂��ѽ���ʩ��оƬ�ͳ��ڹ��Ƶ����ƣ��y���٫@ȡ����оƬ�����������ڡ��Aʢ�D�]��ُ�I������V�棬��������������A���@��AI�𠎣���