

DeepSeek R1 ����̫�����ˣ�
����������صĖ|��������DeepSeek ���ڡ�Ӳ�ء���ȡ�
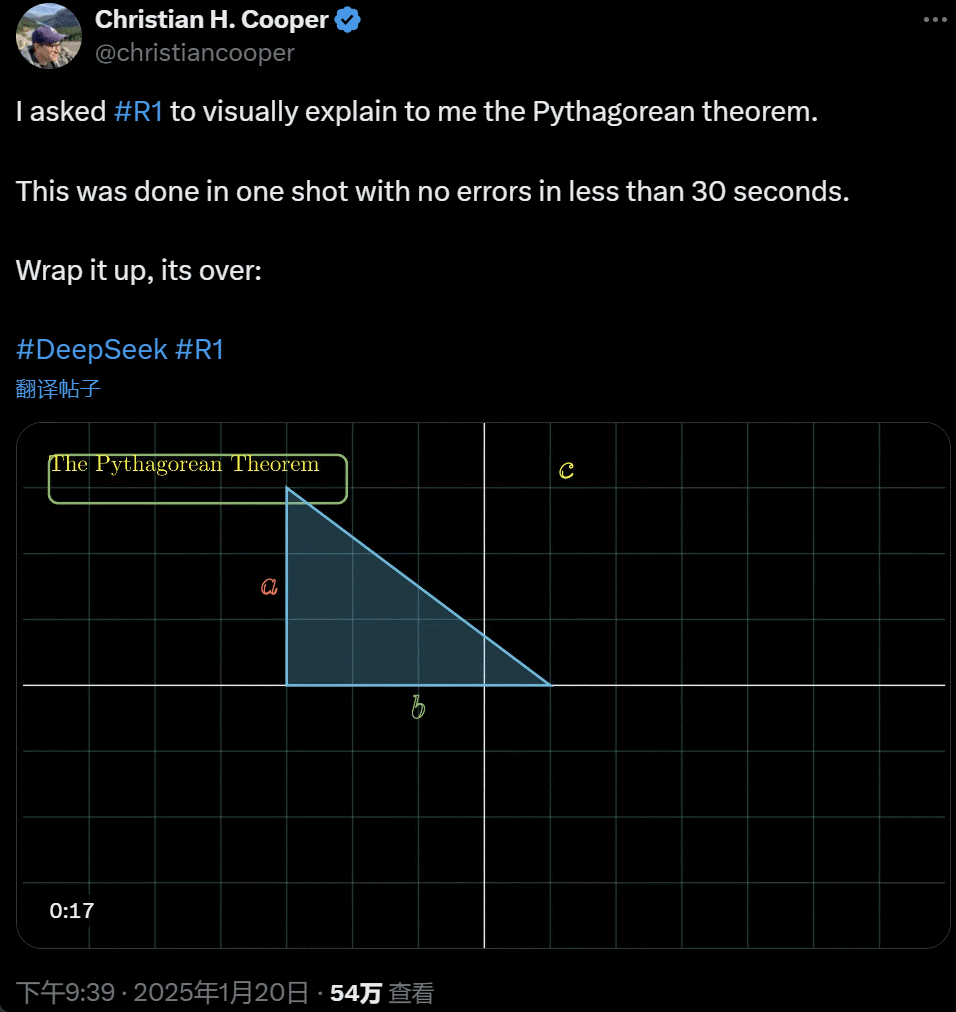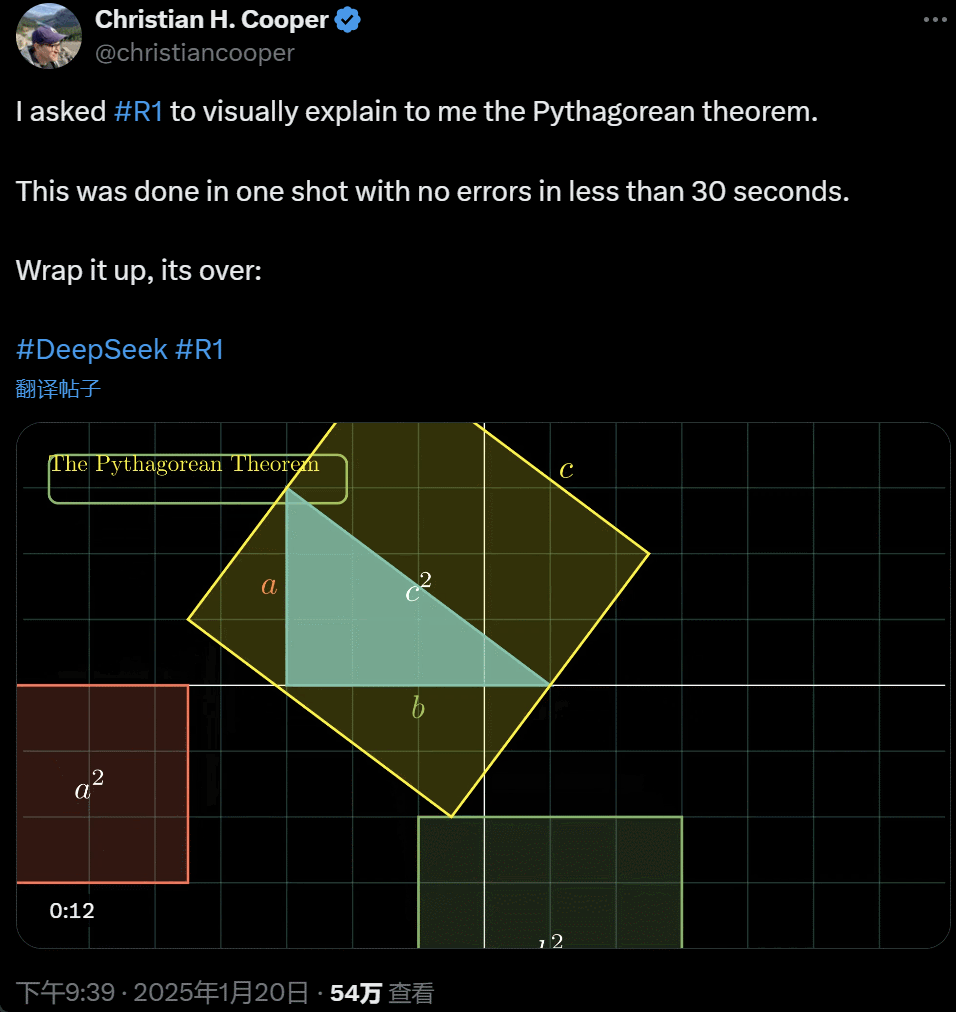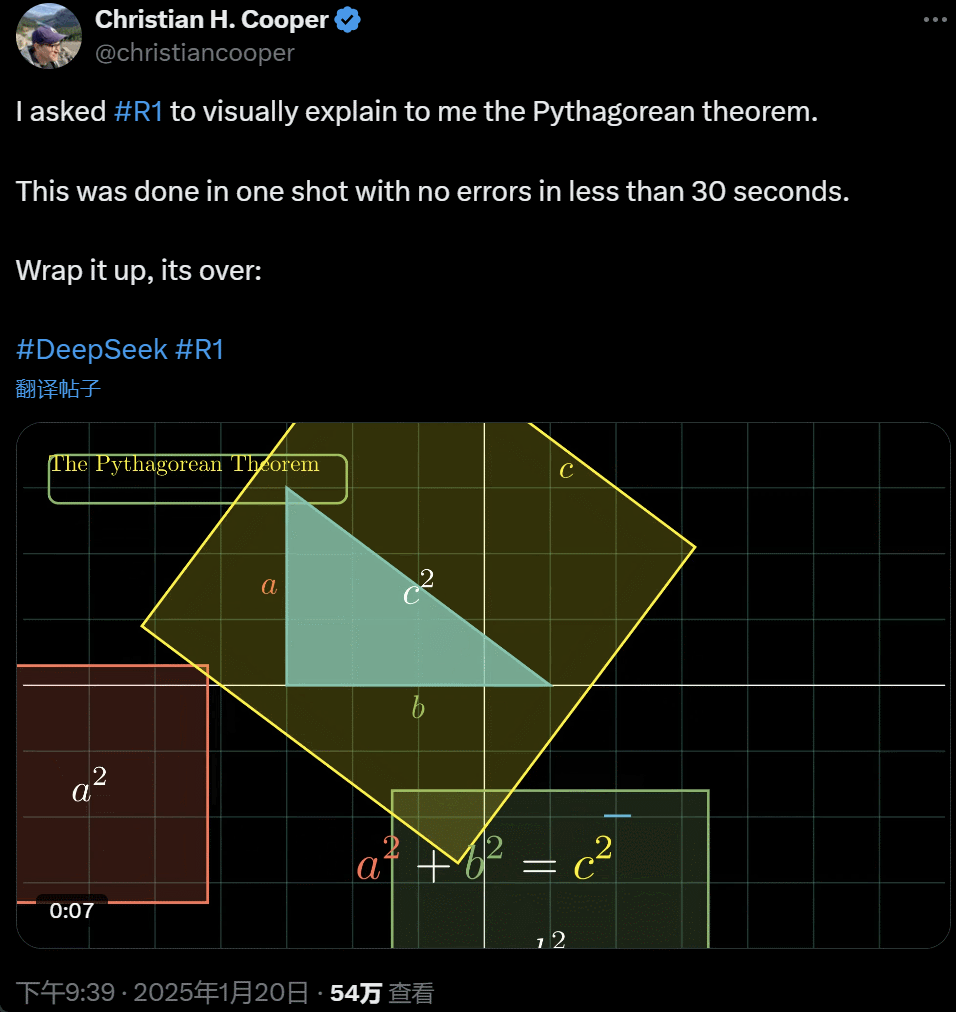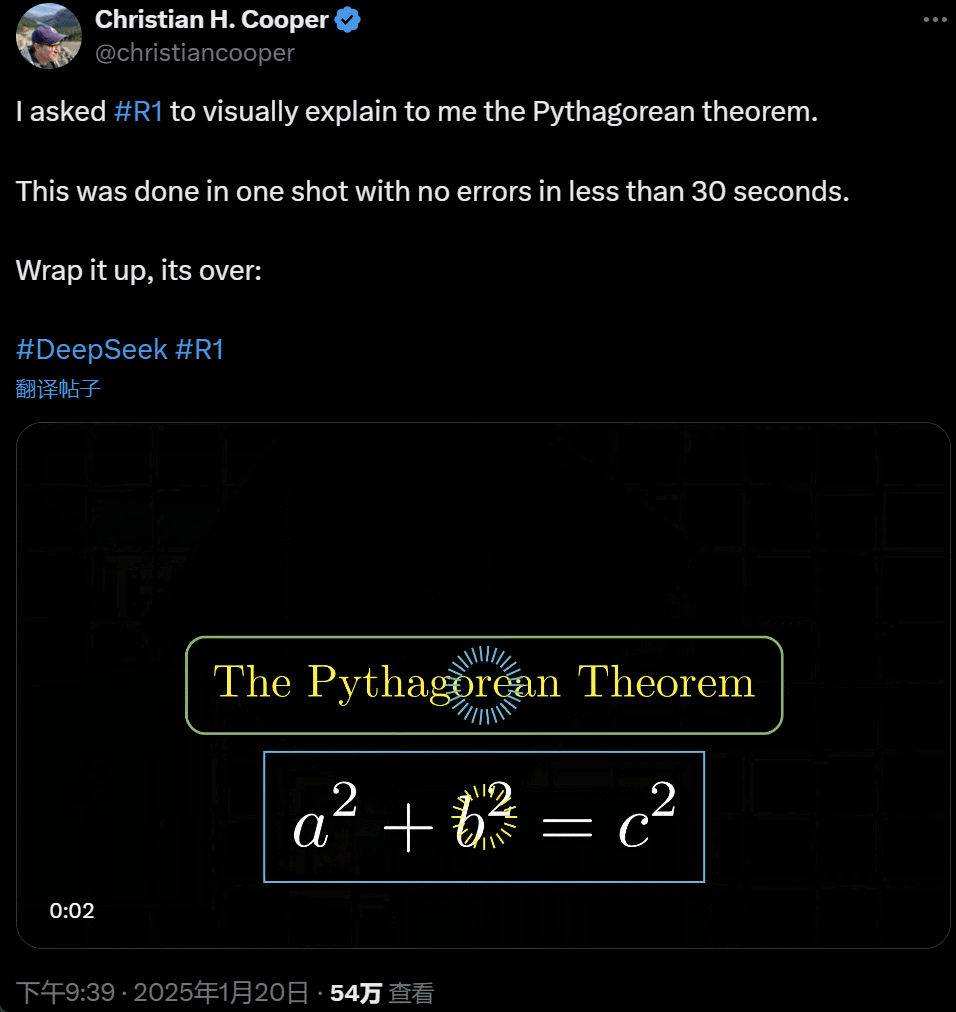
�� R1 Ԕ����ጹ��ɶ������@һ�ж��� AI �ڲ��� 30 ��r�g��һ������ɵģ��]���κ��e�������f��its over��
�ڇ����� AI Ȧ����ͨ�W�Ѱl�F������ď����� AI��߀�_Դ�����W�猣�Ҽ���������Ҫ�^��ֱ����߀��С����Ϣ�Q����� AI ��˾�ѽ����R��
���f�@�����܄��l���� DeepSeek R1�����]���καO��Ӗ���ļ������W��·����������ȥ�� 12 �� Deepseek-v3 �����lչ����� OpenAI o1 ��˼�S��������ƺ��Ǻܿ��_�ɵ��¡�
���� AI ��^�������x���g��桢���Ȍ��y֮�࣬�˂�߀�nj� R1 �������ɣ������������Aһ�� Benchmark ���⣬������I�Ȇ
���Խ�ģ�M������Ҏ�ɡ�
�㲻�ţ�����ģ�����揗��
������죬AI ��^��һЩ���_ʼ����һ헜yԇ ���� �yԇ��ͬ�� AI ��ģ�ͣ����������^������ģ�ͣ���̎��һ��}��������һ�� Python �_����һ���Sɫ����ij���Π�ȏ�����ԓ�Π�����D�����_����ͣ�����Π�ȡ���
һЩģ�����@헡����D���Ρ����ʜyԇ�еı��F��������ģ�͡��� CoreView CTO Ivan Fioravanti �Q�������˹����܌���� DeepSeek ���_Դ��ģ�� R1 ��� OpenAI �� o1 pro ģʽ���������� OpenAI ChatGPT Pro Ӌ����һ���֣�ÿ�����M 200 ��Ԫ��

��߅�� OpenAI o1����߅�� DeepSeek R1�������������@��� Prompt �ǣ���write a python script for a bouncing yellow ball within a square�� make sure to handle collision detection properly�� make the square slowly rotate�� implement it in python�� make sure ball stays within the square����
������һλ�W���� X �ϵ��f����Anthropic �� Claude 3.5 Sonnet �ȸ�� Gemini 1.5 Pro ģ�͌�����ԭ���Д��e�`��������ƫ�x���ΠҲ���Ñ���Q���ȸ����µ� Gemini 2.0 Flash Thinking Experimental���Լ��������f�� OpenAI GPT-4o ��һ����ͨ�^���u����
���@����Ҳ���ֳܷ����µģ�

���@�����ĵ��µľW�ѱ�ʾ��o1 ������ԭ���ܺã��� OpenAI �����ٶ��^���׃���ˣ���ʹ��ÿ�� 200 ��Ԫ�ĕ��T��Ҳһ�ӡ�
ģ�M��������һ������ľ������𡣾��_��ģ�M�Y������ײ�z�y�㷨�����㷨��Ҫȥ�R�e�ɂ����w������һ�����һ���Π�Ă��棩�Εr�l����ײ�������������㷨��Ӱ�ģ�M�����ܻ������@�������e�`��
AI ������˾ Nous Research ���о��T N8 Programs ��ʾ�������˴�s�ɂ�С�r���^�_ʼ����һ�����D��߅���еď�������횸�ۙ��������ϵ���˽�ÿ��ϵ�y�е���ײ������M�еģ������^�OӋ���a��ʹ����������ԡ���
�mȻ����������D�Π��nj����̼��ܵĺ���yԇ�������ڴ�ģ�́��f߀�ǂ����Ŀ����ʹ����ʾ�еļ�׃��Ҳ���ܮa������ͬ�ĽY�����������������K�ɞ� AI ��ģ�ͻ��ʜyԇ��һ���ֵ�Ԓ��߀��Ҫ���M��
�oՓ��Σ����^�@һ�����y֮���҂�����ģ��֮�g��������ͬ�����^�С�
DeepSeek ���µġ������Ԓ��
DeepSeek ������˰����롮�ֻš���
Meta �T���l���Q��Meta ���̎������گ���ط��� DeepSeek��ԇ�D���Џ����κο��ܵĖ|������
�� AI �Ƽ�������˾ Scale AI ��ʼ�� Alexandr Wang Ҳ���_��ʾ���Ї��˹����ܹ�˾ DeepSeek �� AI ��ģ�����ܴ����c������õ�ģ���ஔ��
��߀�J�飬�^ȥʮ�������������һֱ���˹����ܸ�ِ���I�����Ї����� DeepSeek �� AI ��ģ�Ͱl�����ܕ�����׃һ�С���
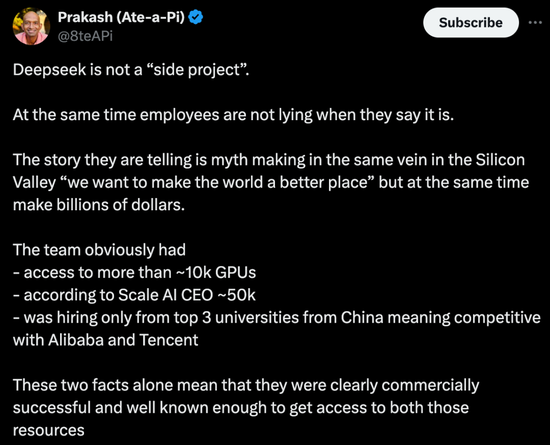
X ���� @8teAPi �t�J�飬DeepSeek ������һ�������I�Ŀ�������������ϣ��・�R����ǰ�ġ��������S����
���^���������S�������Ǯ������ϣ��・�R����˾��Lockheed Martin�������аl�T�����M�w�������T������һ���߶șC�ܡ�����������С�Fꠣ����¼�˻�dz�Ҏ�ļ��g�о��c�_�l���� U-2 �ɲ�C��SR-71 ���B���� F-22 ���ݡ�F-35 �W� II �C���Ǐ��@���߳����ġ�
������@���~��u��׃��һ��ͨ���g�Z���Á������ڴ�˾��M���Ȳ��O���ġ�С���������������������ɶȸ��ߵĄ��Fꠡ�
���o���������Ѓɂ���
һ������ DeepSeek ���д����� GPU�����Q�г��^һ�f�K���� Scale AI �� CEO Alexandr Wang ������ʾ�����_�� 5 �f�K��
��һ���棬DeepSeek ֻ���Ї�����ǰ���Ĵ�W��Ƹ�˲ţ��@��ζ�� DeepSeek �c����Ͱͺ��vӍ����ͬ�ȵĸ�������
�H�{�@�ɂ������Ϳ��Կ������@Ȼ DeepSeek ���̘I��ȡ���˳ɹ��������ѽ����֪�����܉�@���@Щ�YԴ��
���� DeepSeek ���_�l�ɱ���ԓ������ʾ���Ї��Ƽ���˾���ԫ@�ø��N���ӵ��a�N���������늳ɱ����õء�
��ˣ�DeepSeek �dz��п��ֳܴɱ����������á��ں��ĘI��֮���ij���~Ŀ�ϣ�������ij�N�������Ľ��O�a�N����ʽ���ڡ��������˄�ʼ��֮�⣬�]����ȫ�������ؔ�հ��š���Щ�f�h����ֻ�ǡ����^�f������ֻ���u�����ö���
�������ӣ��Ў��c�����_�ģ�
�@��ģ�ͷdz���ɫ���c OpenAI �ɂ���ǰ�l���İ汾�ஔ����ȻҲ�п��ܲ��� OpenAI �� Anthropic ��δ�l������ģ�͡�
��Ŀǰ�������о���������Ҫ��������˾������DeepSeek ģ�͌��ڌ� o1 �汾�ġ����ٸ��M������ DeepSeek ���аl�M�ȷdz�Ѹ�ͣ����A�ڸ����ӭ�^�s�ϣ��������]�г��u�����ף����ֻ�����̡�
DeepSeek ��Ҫ�������B�Լ����˲ţ���������ه�������B�IJ�ʿ���@���Uչ���˲Ŏ졣
�c������˾��ȣ�DeepSeek ��֪�R�a���S�ɡ��[˽����ȫ�����εȷ����ܵ��ļs���^�٣����@�e�`��ʹ����Щ���뱻Ӗ���Ĕ����ē��nҲ�^�١��V�A���٣��Ɏ����٣�Ҳ����]��

���o�Ɇ���Խ��Խ������J�� 2025 �ꌢ���ǛQ���Ե�һ�ꡣ�c��ͬ�r���ҹ�˾����Ħȭ���ƣ����� Meta �����ڽ���һ�� 2GW+ �Ĕ������ģ��AӋ�� 2025 ��Ͷ�Y 600-650 �|��Ԫ����ד��г��^ 130 �f�K GPU��
Meta ������һ���D��չʾ�� 2 ǧ���ߔ��������c�~�s�����D�Č��ȡ�
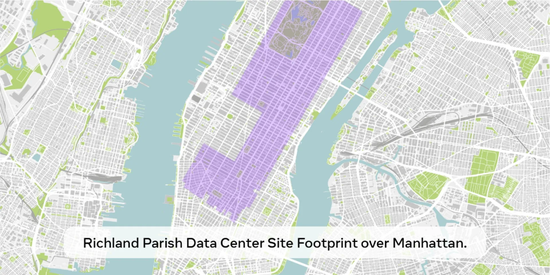
���F�� DeepSeek �ø��͵ijɱ������ٵ� GPU �����˸��ã����ܲ��˽��]��
Yann LeCun��Ҫ���x�_Դ
Hyperbolic �� CTO���τ�ʼ�� Yuchen Jin �l����ʾ���ڃH 4 ��r�g�DeepSeek-R1 ���҂��C���� 4 ������
�_Դ AI �H������]Դ AI ���� 6 ����
�Ї����������_Դ AI ��ِ
�҂����M����Z��ģ�͏����W�����S��r��
���sģ�ͷdz������҂������֙C���\�и����� AI
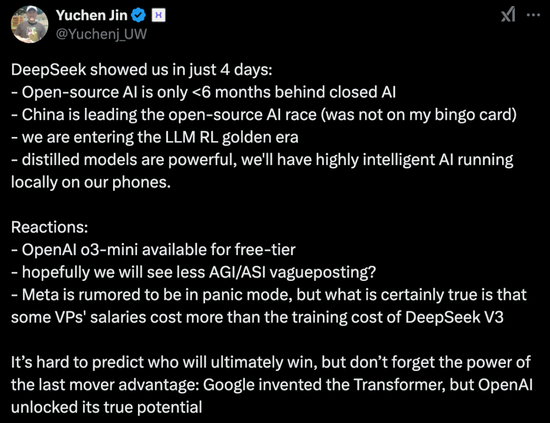
�� DeepSeek ���l���B�i���������^�m������ OpenAI o3-mini ���M���á���^��ϣ���ܜp���P�� AGI/ASI ��ģ��ӑՓ�Լ��� Meta ����ֻŵȡ�
���J�飬�F�ں��y�A�y��K�l���@�٣�����Ҫ��ӛ��l���ݵ������������҂���֪���� Google �l���� Transformer���� OpenAI ���i��������������
���⣬�D�`��������Meta ��ϯ�˹����ܿƌW�� Yann LeCun Ҳ���_���Լ��Ŀ�����
��������Щ���� DeepSeek �����ܾ��J�顰�Ї����ڳ�Խ������ AI�����ˣ��������e�ˡ����_�������ǣ��_Դģ�����ڳ�Խ����ģ�͡���
LeCun ��ʾ��DeepSeek ֮�����@��һ�Q�@�ˣ�������������_���о����_Դ���� Meta �� PyTorch �� Llama���Ы@�档DeepSeek ��������뷨���������˹����Ļ��A�Ϙ�������������Ĺ����ǹ��_�l�����_Դ�ģ�ÿ���˶����ԏ������棬�@�����_���о����_Դ��������

�W�т��ķ�˼߀���^�m���ڌ����¼��g�lչ�d�^��ͬ�r��Ҳ�ܸ��ܵ�һ�c�c�n�]�Ě�գ����� DeepSeek ���ij��F�����ܕ����������y��Ӱ푡�
�������ݣ�
https��//x.com/ivanfioravanti/status/1881969391547683031
https��//x.com/Aadhithya_D2003/status/1882105009548222953
https��//x.com/8teAPi/status/1882836551866204656
https��//x.com/Yuchenj_UW/status/1882840436974428362
https��//x.com/ylecun/status/1882943244679709130
https��//venturebeat.com/ai/tech-leaders-respond-to-the-rapid-rise-of-deepseek/




