

�������g����ģ��Ӗ(x��n)�����_�l(f��)ƽ�_(t��i) Predibase �l(f��)����һ��(g��)��ȫ�йܡ��o����(w��)�����˵��˵ď�(qi��ng)���{(di��o)ƽ�_(t��i)��Ҳ���ׂ�(g��)�˵��ˏ�(qi��ng)���{(di��o)��RFT��ƽ�_(t��i)��
Predibase ��ʾ��DeepSeek-R1 ���_Դ��ȫ�� AI �I(l��ng)��a(ch��n)���˾�Ӱ푣��ܶ������R(sh��)����(qi��ng)���W(xu��)��(x��)�{(di��o)��(du��)Ӗ(x��n)����ģ�͵���Ҫ�ԡ��ܴˆ��l(f��)�������_�l(f��)���@��(g��)�˵��˟o����(w��)����(qi��ng)���{(di��o)ƽ�_(t��i)��

�c���y(t��ng)�ıO(ji��n)��ʽ�{(di��o)��ȣ�RFT ����ه�����Ę�(bi��o)ע��(sh��)��(j��)������ͨ�^��(ji��ng)��(l��)���Զ��x����(sh��)����ɳ��m(x��)�؏�(qi��ng)���W(xu��)��(x��)��ͬ�r(sh��)֧�֟o����(w��)���Ͷ˵���Ӗ(x��n)���������Ĕ�(sh��)��(j��)������Ӗ(x��n)��ģ�͵���(y��ng)�ò��������ͬһ��(g��)ƽ�_(t��i)��ɡ��Ñ�ֻ��Ҫһ��(g��)�g�[�����O(sh��)���{(di��o)Ŀ��(bi��o)���ς���(sh��)��(j��)�����������ǰ�dz���(f��)�s�Ĵ�ģ���{(di��o)���̡�
����չʾ RFT �ď�(qi��ng)��Predibase ���ڰ��� Qwen2.5-Coder-32B-instruct �{(di��o)��һ��(g��)���T���ڌ� PyTorch ���a���g�� Triton ��ģ�� Predibase-T2T-32B-RFT��������(j��)��������Ļ��A(ch��)ģ�ͣ����� DeepSeek-R1��Claude 3.7 Sonnet �� OpenAI o1����(du��)��(n��i)�����_���M(j��n)���˻���(zh��n)�y(c��)ԇ��
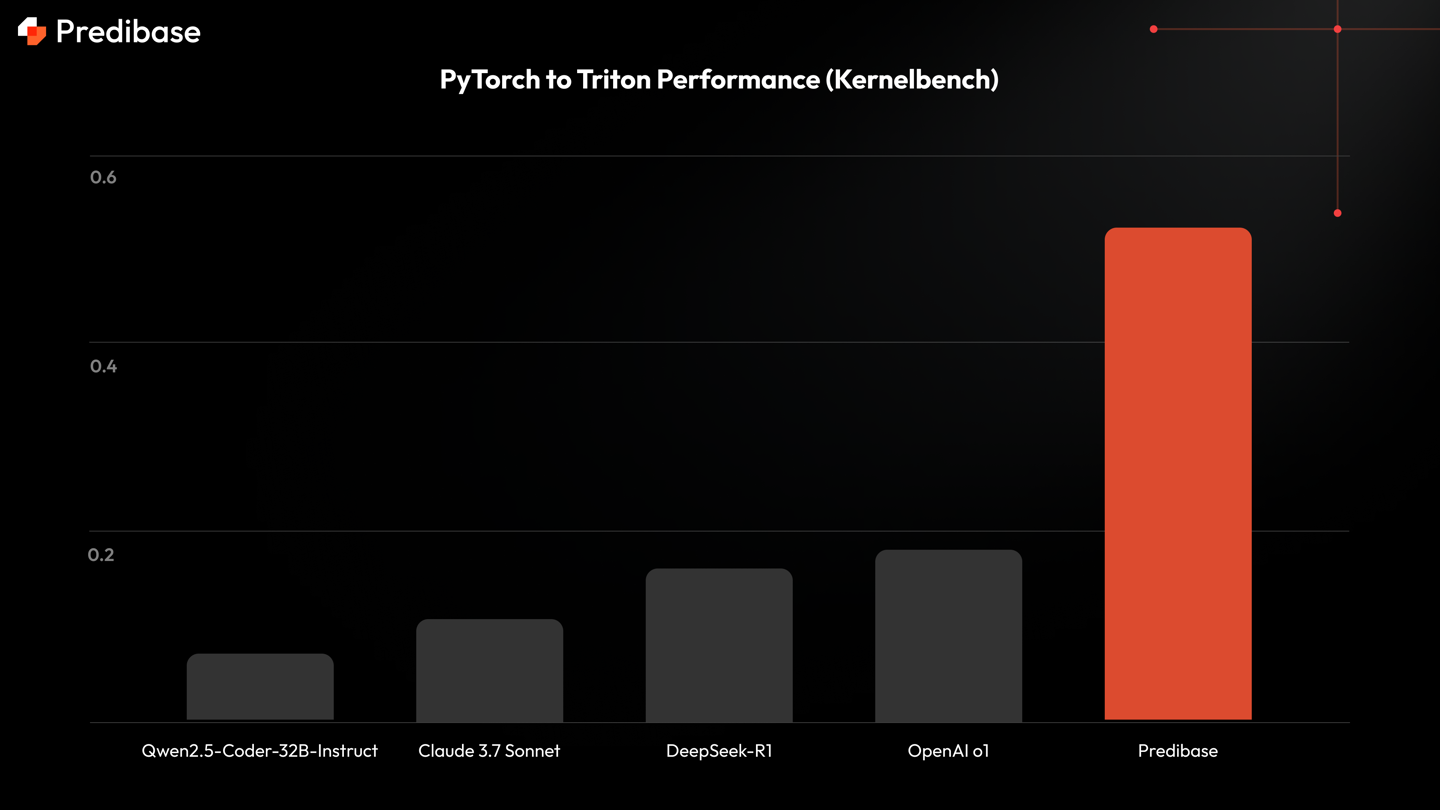
�c���y(t��ng)�ıO(ji��n)��ʽ�{(di��o)������ͬ��Predibase-T2T-32B-RFT ���� RFT �Խ�����ʽ�{(di��o)��ģ���О飬�����ٵĘ�(bi��o)ӛ��(sh��)��(j��)��(y��u)�������΄�(w��)�|(zh��)�����@ʹ��ɞ錣�� LLM �ĸ��ԃr(ji��)�ȡ����������������
ͨ�^ RFT��Predibase ��Ӗ(x��n)���^�̽Y(ji��)�����䆢��(d��ng)�O(ji��n)��ʽ�{(di��o)����(qi��ng)���W(xu��)��(x��)���n�̌W(xu��)��(x��)������ֻʹ����ʮ�ׂ�(g��)��(bi��o)ӛ��(sh��)��(j��)�c(di��n)��
�� Kernelbench ��(sh��)��(j��)�����M(j��n)�еĻ���(zh��n)�y(c��)ԇ�@ʾ��Qwen2.5-Coder-32B-instruct ��(j��ng)�^��(qi��ng)���������_�ʱ� DeepSeek-R1 �� OpenAI �� o1 �߳� 3 ������ Claude 3.7 Sonnet �߳� 4 �����ϣ���ģ��ռ�õĿ��g�sС��һ��(g��)��(sh��)����(j��)��
���_Դ��ַ��
https://huggingface.co/predibase/Predibase-T2T-32B-RFT
�ھ��w�(y��n)��ַ��
https://predibase.com/reinforcement-fine-tuning-playground
�ИI(y��)������͵����|(zh��)���a(ch��n)������")
���� | �����M�����M(f��i) ���o(h��)��Ϣͨ�Ű�ȫ����")
�ɕ�(hu��)")
ͨ�Ŵ��(hu��)")
��(j��)2025�������Ї�(gu��)��(j��ng)��(j��)�v�w���ɾ��|(zh��)���l(f��)չ")