

OpenAI ���գ�3 �� 20 �գ��l�����ģ������Ƴ��Z���D�ı���speech-to-text�����ı��D�Z����text-to-speech��ģ�ͣ������Z��̎��������֧���_�l�ߘ��������ʡ��ɶ��Ƶ��Z������ϵ�y���Mһ���Ƅ��˹������Z�����g���̘I�����á�

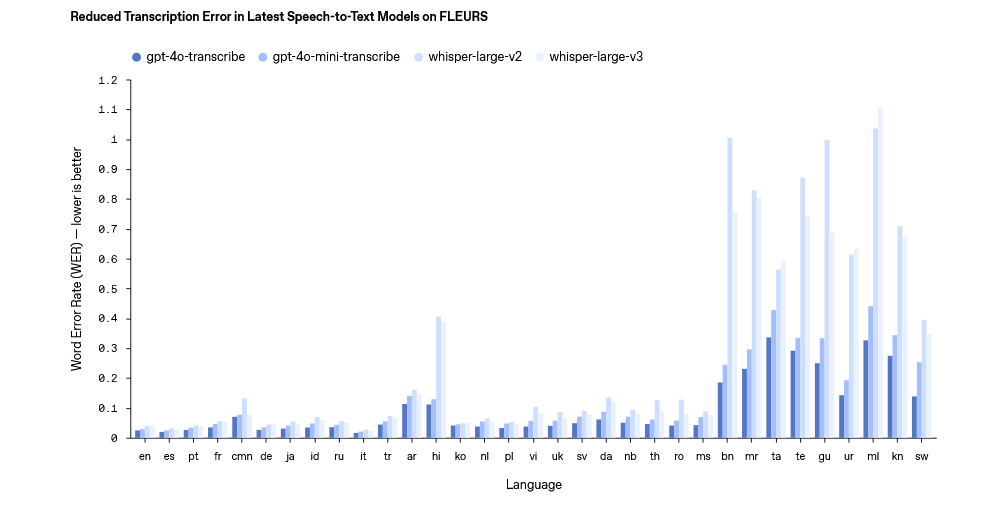
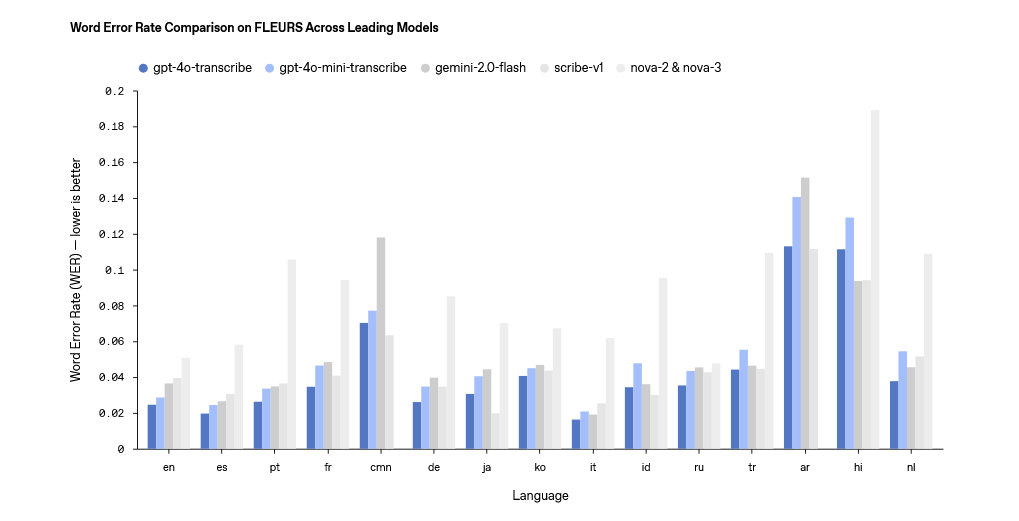
���Z���D�ı�ģ���ϣ�OpenAI ��Ҫ�Ƴ��� gpt-4o-transcribe �� gpt-4o-mini-transcribe �ɂ�ģ�ͣ��ٷ���ʾ�چ��~�e�`�ʣ�WER�����Z���R�e�͜ʴ_���ϳ�Խ�F�� Whisper ϵ�С�
�@�ɂ�ģ��֧�ֳ� 100 �N�Z�ԣ���Ҫͨ�^�����W���Ͷ��ӻ����|�����l������Ӗ�����ܲ����Z���������p���`�R�e�����������s�h������������ͬ�Z���±��F��������
���ı��D�Z���ϣ�OpenAI �����Ƴ��� gpt-4o-mini-tts ģ�ͣ��_�l��ͨ�^��ģ�M���Ŀͷ��������ӹ���������ָ������Z���L���ԑ����ڿͷ����ϳɸ���ͬ���ĵ��Z���������Ñ��w�̈́�����ݣ����������Α��ɫ�OӋ���Ի��������档
IT֮��Ԯ�����Ľ�B����������ģ���M�����£�
gpt-4o-transcribe�����lݔ��ÿ 100 �f tokens �M�� 6 ��Ԫ���ı�ݔ��ÿ 100 �f tokens �M�� 2.5 ��Ԫ��ݔ��ÿ 100 �f tokens �M�� 10 ��Ԫ��ÿ��犳ɱ� 0.6 ���֡�
gpt-4o-mini-transcribe�����lݔ��ÿ 100 �f tokens �M�� 3 ��Ԫ���ı�ݔ��ÿ 100 �f tokens �M�� 1.25 ��Ԫ��ݔ��ÿ 100 �f tokens �M�� 5 ��Ԫ��ÿ��犳ɱ� 0.3 ���֡�
gpt-4o-mini-tts��ÿ 100 �f tokens ݔ���M�Þ� 0.60 ��Ԫ��ÿ 100 �f tokens ݔ���M�Þ� 12 ��Ԫ��ÿ��犳ɱ� 1.5 ���֡�




