

�S��5G���g��Ѹ�Ͱlչ�c�V���ռ�����վ�I�����ľ����A�y���l�P�I���ڶ��վ�Ĉ����У��A�y�������H��ه�ڸ���վ�����Ěvʷ�I������Ϣ��߀���ֿ�����վ�g�Ŀ��gϵ���䌦�A�y�Y�������á����ľ۽��ڶ��վ�龳�µĘI�����A�y���}��̽ӑ�r�g�S�ȺͿ��g�S�����Ӱ푻�վ�I�������A�y��Ч�����ڞ����P�о��c���`�ṩ����ą����ͽ��b��
��վ�I�����A�y����
5G��վ�I�����A�y�����ɞ���һ�N��Ҫ�ļ��g�ֶΣ�ּ����ǰ��֪������׃��څ�ݣ��Ķ�������վ�M���YԴ�ĺ���������{�����ԝM���Ñ�������Ȼ�����վ�I�����A�y���ڏ��s�ĕr�g�����A�y�΄ա��r�g���棬���y�Ĕ����yӋ�͙C���W��ģ�ͣ�����ȡ�I���������������������ޡ����������ȌW��ģ��������L̎���Ǿ��Ԕ��������Ա��_�l�����ڕr�g�����΄��С������e�W�j��CNN�����e�ӵľֲ���֪������Ҫ��ģ�����O�ö��Ӿ��e�ͳػ�������ͨ���y�Բ��L����ه�Pϵ��ѭ�h�W�j��RNN���ģ�ʹ����ݶȱ�ը�͟o����Ӳ���@���в���Ӗ���Ć��}�����⣬�ڿ��g���棬5G��վ�ĘI�����������F�����@�ą^����������

�D1 ��ͬ�^5G��վ�I�������߄݈D
��D 1 ��ʾ���҂��@ȡ�ˁ��Ը��Fվ��סլ�^����У�ȶ����^����挍 5G ��վ�I�������������L�Ƴ������ĘI�����߄݈D���������l�F��ij����·�ε� 5G ��վ�I�����ʬF���@���ij�ϫ���ԣ��䲨���c���ȵĔ�ֵ��H���@�����c֮������ijС�^�� 5G ��վ�I�����߄��^��ƽ�����ͣ�������څ�����c���ٻ�վ�ĘI�����߄ݱ��F��һ����څͬ�ԡ����⣬���@�^��� 5G ��վ�I���������У�����Ͳ��ȵij��F�r�g�������硣�������ϵķ������҂����û�վ֮�g�ڿ��g�ϵ����P�ԣ��Mһ�����ģ�͵��A�y���ȡ�
GCformer�r���A�yģ��
�҂��������ʹ��GCFormerģ�́팦5G��վ�ĘI�����M���A�y��ģ���ɿ���͕r�g��ɂ���ģ�K�M�ɣ���D2��ʾ�����g���棬�҂��������վ�Ĺ����͘I�������������P��վ���c�x�õ����Ӿ�ꇵĿ��g������֮���҂�ʹ�ÈD���e�W�j(Graph Convolutional Networks, GCN)ģ����ȡ��վ�W�j�Ŀ��g�P�Y�����r�����҂������վ�Ěvʷ�I����������ͨ�^1D-CNNģ�K��ȡ�vʷ�����ĕr�g����Ϣ����Ό��õ��Ĕ���ݔ�뵽Transformerģ���С�������Transformer��λ�þ��a�ķ֣��҂�ͨ�^TVOM(Time Variant Optimization Module)�����������������Ϣ�����ģ�Ͳ��@�r���Pϵ������������҂����r�Ճ�ģ�K��ݔ�������M���ںϣ��õ�ģ�͵��A�y�Y����
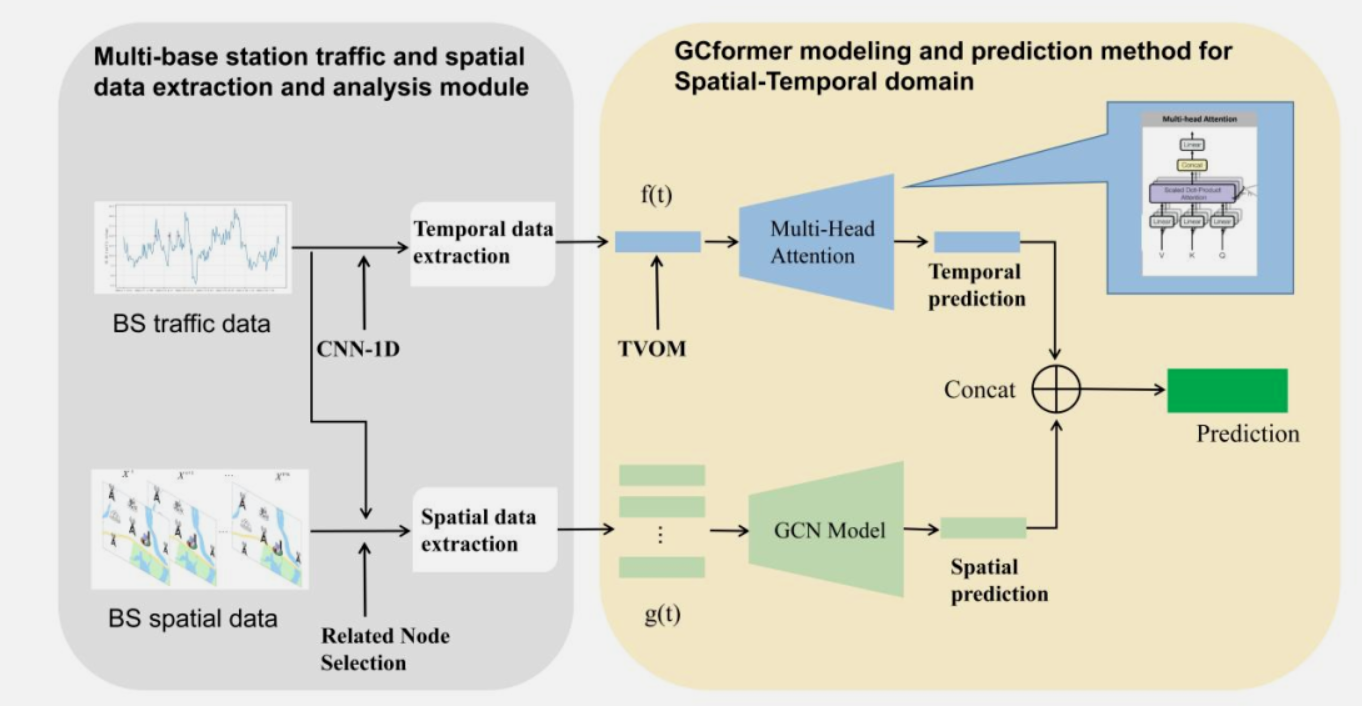
�D2. GCformerϵ�yģ�ͣ�����ͨ�^1D-CNN��TVOMģ�K���M��Transformer�ģ�ͺ�ͨ�^��վ���c�x����GCNģ�͵Ŀ��g��Ϣ��ȡ����
�D���e�W�j�����P��վ���c�x��
�D�W�j(Graph Neural Networks��GNN)��һ�N̎��D��������ȌW��ģ�͡��cCNN, RNN�Ȃ��y����ȌW��ģ�Ͳ�ͬ�����܉�̎���ǚW����¿��g�Ĕ����������c��߅�M����Ϣ���f�͌W�����Ķ��������D�M�оC�Ͻ�ģ�ͷ�����
�D���e�W�j(GCN)�� GNN �е�һ�N������ڂ��y�� GNN��GCN ���ÈD�νY������Ϣ���ڹ��c���e������ʹ�����Ӿ�ꇺͶȾ���M�������ۺϣ��Ķ���ȡ���c�ĸߌӴ�������ʾ����ӳ����վ�g���s�ľW�j�ؓ�Y�����Mһ���ʴ_�ز����g���P�ԡ����w���fGCN �ĺ��ľ����ڈD�Δ����϶��x���e�ӡ��c���y�ľ��e�W�j��ͬ��GCN �еľ��e��ּ�����ÈD�νY�������������c����Ϣ�м�ȡ��Ч�����������PϵԽ�H�������ӌ���ǰ���c��Ӱ푾�Խ��
�ژ���5G��վ�����Ӿ�ꇕr���x����m�Ļ�վ���c�����P��Ҫ�ģ��@���HӰ푔����Ĝʴ_�ԣ�߀�Pϵ���W�j������Ч�������ڴˣ��҂��\�����N�����혋�����Ӿ�ꇣ�һ�ǚWʽ���x������ͨ�^Ӌ��ɻ�վ�g��ֱ�����x�����������ӽ��̶ȣ��˞��u������λ�������վ�Pϵ�Ļ������������Dž^����ͷ����b�ڻ�վ��̎�^����ͣ����̘I�^���WУ�^��סլ�^�ȣ�������I�������Ԯa����ҪӰ푣��ʶ������^����͌����ܻ�λ�����ƵĻ�վ�ֽM���Դ�������վ�g�Į�ͬ�����ǘI���������Է��������������ƶȡ�����ֶΌ���վ�g�I��������չ�_���������ڔ����ӏĶ�S�Ƚ�ʾ��վ�ژI�����ϵ����ƻ���r��������վ�W�j�������c������
�r�g��ģ�ͺ͕r׃����ģ�K
Transformerģ����һ�N���������н�ģ���W�jģ�ͣ������Ȳ���Self-Attention�C���Լ�Positional Encoding������ʹ��ԓģ�����ı�ժҪ���Z�Է��g����Ȼ�Z��̎���΄���ȡ���˃����ijɿ����������Transformerģ��Ҳ���V�����������I������н�ģ���A�y�΄ա���5G��վ�I�����A�y��һ���r�g�����A�y�΄գ�����ÿ���r�g���ڶ���������վ��һ�Ό��H�I��������ˣ�Transformer ģ�Ϳ��Ա��Á팦5G��վ�ĘI�����M�н�ģ���A�y�������P�ĘI�՛Q���ṩ������������
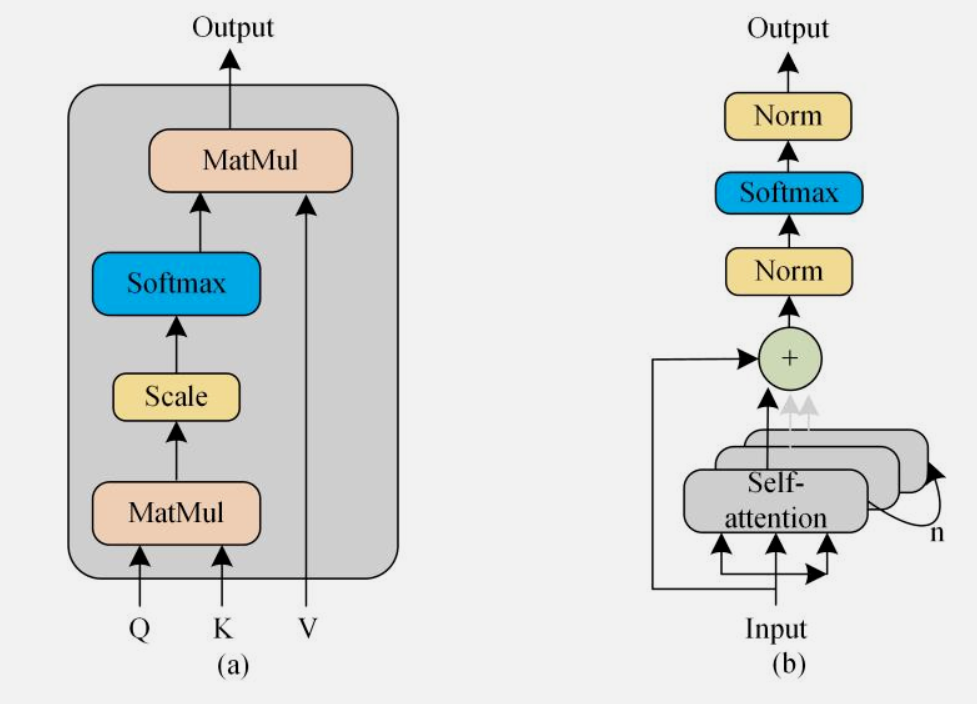
�D3 Self-Attention and Multi-head attention
���⣬���y��Transformerģ����ݔ�딵��λ�õIJ�ͬ��ͨ�^Positional Encoding�ķ�������ݔ�딵��֮�g������Pϵ�������@�N�^��λ�þ��a�ķ�������̎��5G��վ�I���������r��ȱ���ɿ���ᘌ��Եĕr�g���еķ�������ˣ��҂����Time Variant Optimization Module(TVOM)����Transformerģ���еĕr����Ϣ��TVOMͨ�^Ӌ�㔵���е����P�ԣ�����ȡ5G��վС�^�ĘI�����������������Ϣ���������ڔ������뵽Positional Encoding���֡�
���w���f���҂�����Prophetģ�ͷ���5G��վ�Ñ����I������������ȡ�����w����������Ϣ���S���҂�ͨ�^��С���˷��M�������M�ϣ�ԓ�������OӋ�����������͌��H�������`������Ŀ�˺��������M�ϵ������M�Ѓ�����ͨ�^��С���`���ƽ��ֵ�����@����Ķ��ʽ��ϵ�����M�����������헌����ĵĺ������_ʽ����Ӗ��ģ�͵��^���У���С�^ID����ƥ��˺�������ݔ�딵������ʼ�r�̌�����Q����헺������Ķ����aԭʼ��Positional Encoding�����o���ڕr�g���Д����б�ʾ����Ć��}��
���Y
���@��о��У��҂�����5G��վ�I���������ĕr�����ԣ������һ����ȌW���ܘ�GCformer��������Ч������������վ֮�g���g���P�Ե��Pϵ���҂��xȡ�˻�վ���x���^����͡��������ƶȽ����C����Ϣ�����Ӿ�ꇣ���ʹ��GCNģ�K��ȡ����g�Pϵ������GCformer�ĕr�g��ģ�K�^����Transformerģ�ͣ�ʹ��Self-Attention������ȡ�I��������֮�g���Pϵ������ͨ�^1D-CNN��TVOMģ�K�Mһ���������@�����еĕr����Ϣ��




